In February 2023, Cyclone Freddy made landfall in Mozambique, proceeding to cut across Southeastern Africa. Floodwater swallowed roads which had been bustling just hours before. In coordination centres across Zambezia and Sofala provinces, responders pulled up satellite imagery already days old, tracing routes on maps that no longer match the ground. A bridge marked as standing had collapsed. A warehouse of medical supplies sat twelve kilometres from the people who needed it, separated by water that hadn't been there when the route was planned.
There is a significant gap between when a disaster strikes and when the data needed to respond to it becomes available. In this time, terrain analysis depended on GIS specialists manually digitising remote sensing imagery. Feature by feature, road by road, before anyone could make a routing decision. This assumes skilled volunteers are available on demand and that accurate data can be sourced on demand and neither is guaranteed.
Our Solution
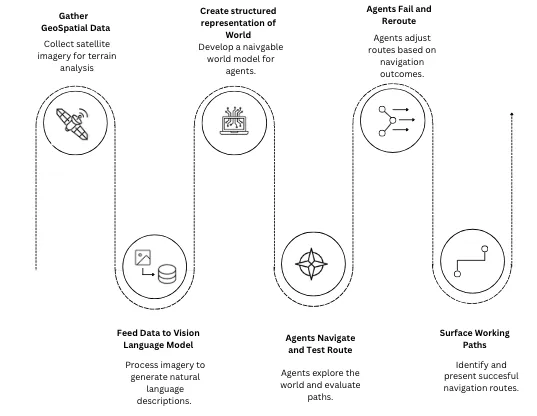
What if the terrain could map itself? This is the premise we started with. Take raw remote sensing data, feed this to a vision language model (VLM) which describes what it sees. From this we can build a representation of the physical world with enough structure for autonomous agents to navigate, reason about, and route through it. By then simulating an exogenous shock to this system, such as a flood, we can observe how agents move through the world as it changes , testing routes, failing and rerouting over successive generations to surface the paths that actually work given the terrain. These routes can then help real-world responders with planning.
Our project FRAM, named after the Norwegian vessel which carried Fridtjof Nansen's polar expeditions in the 1890s, means "forward" in Norwegian. Nansen designed the ship to work with the environment rather than against it, its hull was shaped to rise above crushing pack ice instead of resisting it. This felt fitting. We weren't trying to fight the data problem using more analysts or faster manual workflows. We wanted to build something that understood a territory as it changed.
Building an Environment
The world in 200m Cells
The first problem was building a digital representation of the world. We started with a base dataset of satellite imagery and OpenStreetMap of a chosen target area. For the hackathon build, we used the London borough of Southwark. The area gets decomposed into H3 hexagonal cells, each roughly 200 metres across. Every cell carries structured attributes: building density per square kilometre, road counts broken down by type (footway, cycleway, primary, residential), and boolean flags for land-use categories (commercial, industrial, water, green space). Finally, this telemetry data is enriched with a visual description provided by the VLM pass.
Batch Processing with DoubleWord
We needed a way to batch-process hundreds of satellite image tiles through a VLM and get back natural-language descriptions that our agents could actually reason about. DoubleWord provides API endpoints for this kind of workload, high-throughput multimodal inference that can handle the volume of a full grid without us standing up and managing our own serving infrastructure. The pipeline works like this: for each H3 cell, we crop the corresponding satellite tile, send it to DoubleWord's VLM endpoint, and get back a plain-text description of what the model sees. "Dense residential area with narrow streets, a small park visible to the southeast, no visible water." These descriptions get attached to each cell alongside the structured attributes, giving our agents both quantitative data (density: 4,200 buildings/km²) and qualitative context (narrow streets, small park) to reason about when making movement decisions.
From Grid to Simulation
We prototyped in NetLogo first, a natural starting point for agent-based modeling as we wanted to validate the digital representation with classical agents before introducing LLM reasoning. Once the grid world behaved as expected, we ported everything to Mesa, a Python ABM framework where we had full programmatic control over the simulation loop and could make API calls to an LLM at every agent step. The Mesa environment uses a dense NumPy array. Every cell carries a terrain type, traversal cost, walkability flag, hazard level, and occupancy count, all accessible to our agents. When we simulate an external shock, in this case a flood, hazard levels update dynamically across the grid each tick. Agents don't see the whole board but perceive the changing world through a local awareness radius meaning their decisions are made based on local information, similar to those in a real situation on the ground.
LLM’s as Objective Functions
FRAM diverges from traditional agent-based models in how agent's goals are defined. In a conventional ABM, an agent's objective is defined as a mathematical function and agents evaluate options numerically. This, we believe, constrains the agent to dimensions the modeller thought to hardcode. FRAM agents have no numeric objective function. The goal for our agents is defined in natural language. We endow agents with a personality ("An elderly resident who walks slowly and avoids crowds") and a description giving broader context. FRAM agents have no numeric objective function. Instead, each agent is instantiated with three natural-language strings: a goal ("Reach the southern boundary before the flood cuts off the exit"), a personality ("An elderly resident who walks slowly and avoids crowds"), and a scenario description giving broader context. The goal is the objective function which is interpreted by a language model.
class LLMAgent:
def __init__(self):
self.goal = "" # "Reach the southern boundary before the flood cuts off the exit".
self.personality = "" # "An elderly resident who walks slowly and avoids crowds".
self.scenario = "" # Natural-language context about the simulation.
self.learnings = "" # Bullet-point text from prior generation (empty for gen 1)
self.awareness_radius = 8 # cells
The Simulation Loop
Each tick of the simulation, every agent runs a three-phase cycle: perceive, decide, execute.
Perceive: The agent gathers everything visible within its awareness radius. walkable neighbours, hazard levels and their rate of change, the direction hazards are moving from, nearby agent density, pheromone readings, distance and direction to the nearest exit.
Decide: all of that perception data gets assembled into a prompt alongside a numbered list of possible moves, each annotated with cost, hazard level, and occupancy. The list is randomly shuffled as a countermeasure against language models' known tendency to favour options presented first or last. The prompt goes to Nemotron, which returns a reasoning chain and an action index.
Execute: the agent moves, updates the occupancy grid, and deposits pheromones. This is a visited signal plus a danger pheromone proportional to the hazard it just experienced.
NVIDIA's open-source Nemotron model handles all agent-level reasoning. Using BrevLab, we wrapped the model in a FastAPI service and exposed it as an endpoint for our agents to call. We chose Nemotron because it was fast enough to keep simulation cycles tractable. DoubleWord also provides access to Nemotron 120B, which opens the door to scaling up agent reasoning.
What Agents Taught Each Other
At the end of each generation, the system collects every agent's journey: where it started, where it ended up, a sampled trajectory, its last reasoning traces, its personality, its goal. We pipe all of this to Nemotron with a meta-prompt: distill this into five to fifteen bullet points of concrete, actionable lessons.
The table below shows learning traces from the first generation.
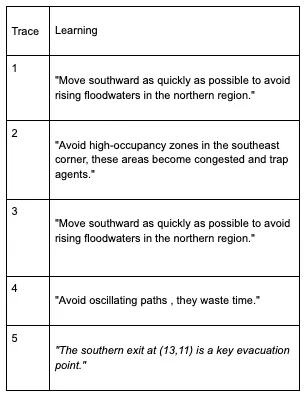
Observations from simulation runs
Comparing the behaviour of the first generation agents to that of the second, we find that generation agents are chaotic. Figure 1, below, shows Agents fan out in every direction, many heading straight toward rising floodwater because they have no prior information about where the hazards emerge. They cluster at chokepoints, creating congestion that traps agents behind each other. Some fall into oscillation loops, moving between two adjacent cells tick after tick, unable to commit to a direction. A meaningful number die or get stuck.
Fig (1) - First generation Simulation Run
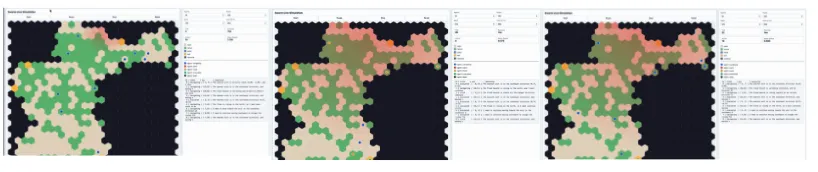
Figure (2) below shows the simulation from the second generation. Generation two reads the learnings and we see this immediately. Agents move south earlier and more decisively. They avoid the southeast corner where generation one discovered congestion traps and converge on the southern exit that generations one's survivors identified as the dominant evacuation point. The oscillation loops largely disappear given instructions previously to "avoid oscillating paths, they waste time".
Fig (2) - Second Generation Simulation Run

The first time we watched a generation-two agent route cleanly around the southeast bottleneck that had killed half of generation one we’d noticed that this behaviour was quite similar to that of a human planner, who with the same information would make the same call. Generating that information had required generation one's agents to walk into the flood and not come back.
What our Agents Learned on Their Own
There are a number of different emergent behaviors which we’d not anticipated. Congestion avoidance was not hardcoded but it appeared because agents crowding into the same cells created a bottleneck that the generational summary flagged as a problem. Neither was an understanding of chokepoint’s initially modelled, one exit emerged as strategically dominant through agent experience, The observation that "agents with a clear goal succeed more than those with ambiguous objectives" came from the summarisation model noticing a pattern in which agents survived, not from anything we designed into the system.
Conclusion
With FRAM, we were able to show that a single generation of natural-language feedback, distilled from each agent’s experience to those in the next generation measurably changes collective behaviour in the right direction. We see that language models are able to serve as objective functions for agent-based simulations, with generational memory that can transmit spatial reasoning across simulation runs, and coherent routing strategies can emerge from the interaction of natural-language goals, environmental stigmergy, and shared experience. The routes identified in response to the external shocks are not ones a human responder would have difficulty replicating given the same information. But the information took generations one's agents dying to produce. We had been quickly able to surface a simulation of flood response, requiring no human analyst to interpret satellite imagery, digitise terrain features, or manually evaluate routing options. Closing the gap between a disaster happening and accurate, actionable data existing.
What has not yet been shown are long-horizon improvements. The system retains one generation of memory, and future work to look at what would happen over ten, twenty or more generations. We would also aim to track evacuation curves and survival rates across generations to investigate any convergence, or identifying where improvement plateaus.